SLURM
Slurm (Simple Linux Utility for Resource Management) is an open-source workload manager/scheduler for the M3 MASSIVE cluster. It was created back in the mid-2000s by SchedMd and now it's used by approximately 65% of the world's supercomputers. Slurm is basically the intermediary between the Login node and compute nodes. Hence, the Slurm scheduler is the gateway for the users on the login node to submit work/jobs to the compute nodes for processing.
Slurm has three key functions.
- It provides exclusive and/or non-exclusive access to the resources on the compute nodes to the users for a certain amount of time. Hence, the users can perform any computation with the resources.
- It provides a framework to start, execute, and check the work on the set of allocated compute nodes.
- It manages the queue of pending jobs based on the availability of resources.
The below diagram shows how Slurm works in the context of M3 MASSIVE.
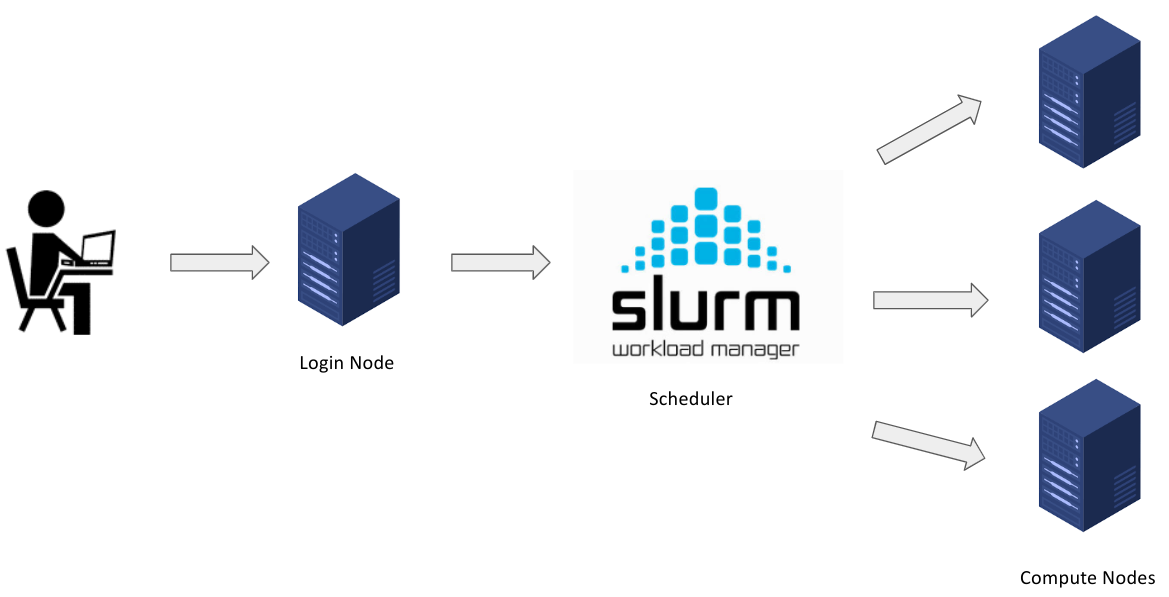
Slurm Architecture
Slurm has a centralized manager, slurmctld, to monitor resources and work. Each compute server (node) has a slurmd daemon, which can be compared to a remote shell: it waits for work, executes that work, returns status, and waits for more work. There is an optional slurmdbd (Slurm DataBase Daemon) which can be used to record job accounting information in a database.
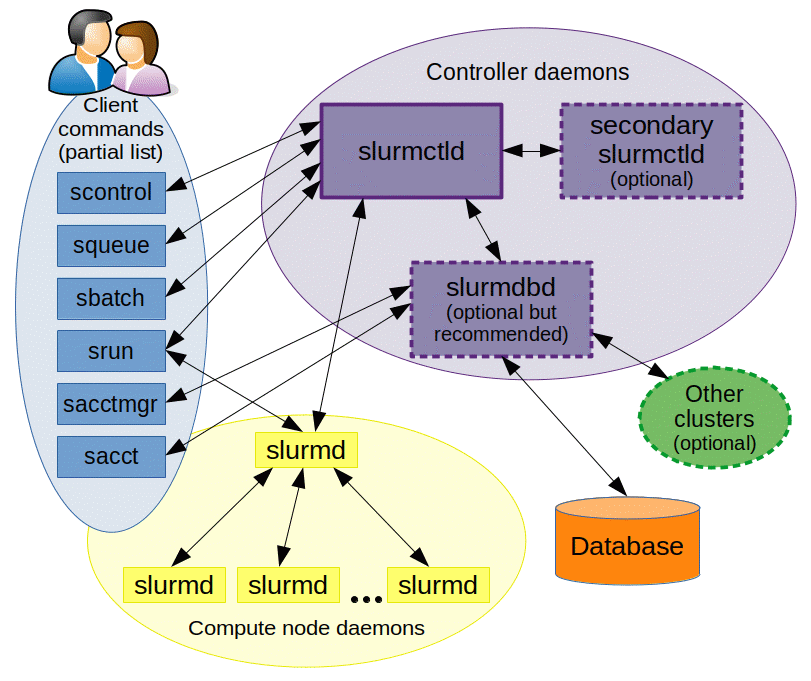
Basic Slurm Commands
Slurm provides a variety of tools for users to submit and manage jobs along with viewing info about them. These commands can be used interactively (on a terminal) in the login node.
| Commands | Syntax | Description |
|---|---|---|
sinfo | sinfo | Get information about the resources on available nodes that make up the HPC cluster. |
sbatch | sbatch <job-id> | Submit a batch script to Slurm for processing. |
srun | srun <resource-parameters> | Run jobs interactively on the cluster. |
skill/scancel | scancel <job-id> | End or cancel a queued job. |
squeue | squeue -u | Show information about your job(s) in the queue. The command when run without the -u flag, shows a list of your job(s) and all other jobs in the queue. |
sacct | sacct | Show information about current and previous jobs. |
Slurm Job Scripting
Slurm job scripts are very similar to bash scripts but you will have to use a set of Slurm-specific directives (flags beginnig #) and Slurm-specific & Bash commands.
In creating a Slurm script, there are 4 main parts that are mandatory in order for your job to be successfully processed.
- Shebang: The Shebang command tells the shell (which interprets the UNIX commands) to interpret and run the Slurm script using the bash (Bourne-again shell) shell.
This line should always be added at the very top of your SBATCH/Slurm script. (Same as all Bash scripts)
- Resource Request: In this section, the amount of resources required for the job to run on the compute nodes are specified. This informs Slurm about the name of the job, output filename, amount of RAM, Nos. of CPUs, nodes, tasks, time, and other parameters to be used for processing the job.
These SBATCH commands are also know as SBATCH directives and must be preceded with a pound sign and should be in an uppercase format as shown below.
#SBATCH --job-name=TestJob
#SBATCH --output=TestJob.out
#SBATCH --time=1-00:10:00
#SBATCH --ntasks=1
#SBATCH --cpus-per-task=1
#SBATCH --mem-per-cpu=500M
Some of the various resource request parameters available for you on Slurm are below:
ntasks: The number of tasks or processes to run.mem: The amount of memory to allocate to the job.time: The maximum amount of time the job can run for.job-name: The name of the job. Up to 15 characters.partition: The partition to run the job on.mail-user: The email address to send job status emails to.mail-type: The types of emails to send.
Note: In the case of M3, a task is essentially the same as a process. This is not the same as a cpu core. You can have a task that uses one or multiple cores. You can also have multiple tasks comprising the same job, each with one or multiple cores being utilised. It can get quite confusing, so if you are unsure about what you need, just ask. There is also more information in the M3 docs.
There are a lot more options that you can use, and you can find a more complete list here.
In particular, if you want to run multithreading or multiprocessing jobs, or you need a gpu, there are more options you need to configure.
- Dependencies: Load all the software that the project depends on to execute. For example, if you are working on a python project, you’d definitely require the python software or module to interpret and run your code. Go to Chapter 5.6 for more info on this.
module load python
- Job Steps Specify the list of tasks to be carried out.
srun echo "Start process"
srun hostname
srun sleep 30
srun echo "End process"
Putting it all together
Please note that the lines with the double pound signs (##) are comments when used in batch scripts.
## Shebang
#!/bin/bash
## Resource Request
#SBATCH --job-name=TestJob
#SBATCH --output=TestJob.out
#SBATCH --time=1-00:10:00
#SBATCH --ntasks=1
#SBATCH --cpus-per-task=1
#SBATCH --mem-per-cpu=500M
## Job Steps
srun echo "`Start process`"
srun hostname
srun sleep 30
srun echo "`End process`"
In the script above, 1 Node with 1 CPU, 500MB of memory per CPU, 10 minutes of Walltime was requested for the tasks (Job steps). Note that all the job steps that begin with the srun command will execute sequentially as one task by one CPU only.
The first job step will run the Linux echo command and output Start process. The next job step(2) will echo the Hostname of the compute node that executed the job. Then, the next job step will execute the Linux sleep command for 30 seconds. The final job step will just echo out End process. Note that these job steps executed sequentially and not in parallel.
It’s important to set a limit on the total run time of the job allocation, this helps the Slurm manager to handle prioritization and queuing efficiently. The above example is a very simple script which takes less than a second. Hence, it’s important to specify the run time limit so that Slurm doesn’t see the job as one that requires a lot of time to execute.
Interactive jobs
Sometimes you might want to actually connect to the node that you are running your job on, in order to see what is happening or to set it up before running the job. You can do this using the smux command. Similar to regular batch jobs, you can set options when you start the interactive session. An example of this is:
smux new-session --ntasks=1 --time=0-00:01:00 --partition=m3i --mem=4GB
This will start an interactive session on a node with 1 cpu, 1 minute of time, and 4GB of memory. There are again other options available, and you can find a more complete explanation here.
Connecting to interactive jobs
Typically when you start an interactive job it will not start immediately. Instead, it will be queued up once it has started you will need to connect to it. You can do this by running smux a, which will reconnect you to the session. If you want to disconnect from the session but leave it running, you can press Ctrl + b followed by d. This will disconnect you from the session, but leave it running. You can reconnect to it later using smux a. If you want to kill the session, if you are connected just run exit, otherwise if you are in a login node run scancel <jobid>. You can find the job id using show_job.
Checking the status of jobs, finding out job IDs, and killing jobs
A couple of useful commands for general housekeeping are:
squeue: This will show you the status of all jobs currently running on M3.show_job: This will show you the status of all jobs you have submitted.squeue -u <username>: This will show you the status of all jobs submitted by a particular user currently running.scancel <jobid>: This will kill a job with a particular job id.scancel -u <username>: This will kill all jobs submitted by a particular user.show_cluster: This will show you the status of the cluster, including any nodes that are offline or in maintenance.